Can you really scale with any language?

A couple days ago I hopped on LinkedIn to update my job and to make a company page for a startup I’m working on. When I finished working on the company description, I clicked the home tab and then proceeded to free fall through the feed for the next fifteen minutes. Happily, I did not see as many of those AI articles begging for contributors! However, I did see some of the other posts that, in my opinion, make LinkedIn such an icky place. You can picture it now: hundreds of incensed comments, a smug little mugshot, and the crown jewel of a one-liner sticking out just above the fold, triumphantly proclaiming
Any language can scale, and anyone who tells you any different is a Communist.
Okay, in truth I can’t remember exactly how the post was worded, but it felt like there was some McCarthyism in it. It’s not surprising since language choice has always been a spicy topic, but I do think platforms like LinkedIn have exacerbated the problem. The short format, and equally short response format, does not make for good discussion.
It’s a shame because scalability is a topic worth discussing well, and language choice is an important subtopic. It’s one I am intimately familiar with as a DevOps-adjacent backend engineer, and now as an SRE, and frankly it has real ramifications on businesses and, no joke, on the planet. I don’t want to let LinkedIn have the last word. Instead, I’d like to do it justice with a full article.
So let’s clear it up: can you really scale with any language? I am convinced that the theoretically correct answer is yes. But if we stop here, this article will be about as useful as the LinkedIn content that brought us here. Let’s go deeper.
What is scale?
What are we actually claiming when we say that languages can scale? At its heart, scalability is about handling more load, where load can be thought of in terms of requests, or traffic, or the size of a dataset, depending on the problem space your application lives in. If we boil it down a little further, it’s really a question of operations: can you keep up with the operations necessary to continue running your workload? More requests, more traffic, and more data all mean more operations are required. Scalability is the measure of how well your application can keep up with additional operations—either by adding more resources, or by controlling the rate of growth, as we’ll see.
In some sense, everything is scalable. Imagine we’re talking about algorithms for a second here: binary search takes logarithmic time in the worst case, while a search through unsorted data could require you to look at the whole list, meaning it takes linear time in the worst case. We’d say that binary search is more scalable because the number of operations required to keep up with additional data is much lower. You’re controlling the rate of growth of the number of operations. But does that mean linear search doesn’t scale? Of course not. You can still search and get the answer; it still handles the extra data. It just takes more operations, which means you need more time, or you need more compute and the ability to parallelize to do it in the same amount of time. But it scales!
So what do people mean when they say “XYZ doesn’t scale”? Is it that people on LinkedIn have no idea what they’re talking about? Well, sometimes yes. But I think more often there are just assumptions at play that are important, that also happen to be obscuring the real substance of the argument.
Assumptions
Let’s look at our algorithm example again. Why don’t we typically consider algorithms with an exponential runtime scalable? What’s the assumption at play?
Well, pretend we’re computing Fibonacci numbers. We have to take two numbers and add them to get the next. But to get those two numbers, we had to compute them by adding the previous two numbers together, and so on. Let’s say addition takes a nanosecond (it’s probably a little faster than that, but we’re generalizing since we have to leave the CPU registers as the dataset grows). In that case, computing the first number, 2, takes one nanosecond. To get 3, we’d have to add 2, which took one nanosecond to compute, to 1, which will take another nanosecond, for a total of two nanoseconds. To get 5, we’d have to compute 2 in one nanosecond, and 3 which took two nanoseconds, and add them at the cost of another nanosecond for four nanoseconds total. To get 8, we’d need seven nanoseconds. For 13, twelve nanoseconds. Overall, we’d expect the time requirement to keep growing with the Fibonacci sequence, which grows by about 1.618 times per iteration. Therefore, the runtime is estimable by 1.618^n.
With that in mind, we can easily predict how long it’d take to compute any number in the sequence. For instance, computing the 50th number in the Fibonacci sequence would take 28,114,208,661 nanoseconds, which is about 28 seconds. That’s already a long time to sit and wait to the TikTok generation. But it gets much worse: by the time we try to calculate the 100th number, we’d need 790,408,728,675 seconds (not nanoseconds, but seconds), which is about 25,000 years.
So what can we say? Everything scales, but not everything is scalable when we start to apply constraints. In this case, my lifetime is a pretty hard cap for how much time I can allocate to a program. An exponential algorithm scales its resource consumption (namely, time) at a rate that quickly violates that cap, therefore we typically wouldn’t consider it to be scalable.
But this also shines some light on the assumptions we have about exponential algorithms. In this case, I just assumed none of us will be alive in 25,000 years to see our calculation through. I also assumed you were assuming the same thing, so we’d be in unspoken agreement about the conclusion. I assumed we wouldn’t be using memoization or dynamic programming to speed things up, nor would we be splitting this computation across multiple CPUs in parallel. I assumed each operation would take a nanosecond. I also assumed we would need to compute something as high as the 100th term in the sequence, or possibly higher. And perhaps most nefariously, since I was the one writing I assumed you all would just smile and nod along and not ask any questions about my implementation (though in reality I know half of you were shaking your head as I proposed recalculating Fibonacci numbers we had already computed).
This is exactly what happens on LinkedIn. It’s no wonder people end up talking past each other. We can’t debate conclusions effectively when we haven’t taken the time to agree on our assumptions. You could poke holes in just about any of those assumptions I made, except maybe the whole being alive in 25,000 years thing. We let one known fact—that exponential runtime really blows up—render the rest of the discussion moot. But what if addition actually is much faster than a nanosecond? What if we do memoize? What if we only need the first 10 terms? Sure, it doesn’t scale within constraints past a certain point, but does that matter for our use case? This is where the discussion gets real, and you make real tradeoffs that are applicable to real use cases and real businesses and real users. We need to unearth the assumptions if we want to have a discussion with substance.
Substance
Let me ask again: can you really scale with any language?
I still think the theoretical correct answer is yes, but let me now explain all of the assumptions going into that. For one, my answer is kind of like a high school physics problem where we pretend air resistance doesn’t exist: I’ve assumed there are no physical constraints, and that the difficult details of temperature regulation in data centers and packet loss over networks and all that can be ignored. I’ve assumed we’re in a problem space that allows us to write stateless applications that we can scale horizontally ad infinitum. I’ve also assumed we’re arranging our data storage such that it can scale with our compute too, without exhausting our supply of connections or instance RAM or IP addresses. Basically I’ve assumed that all of these really difficult and thorny problems are just magically handled by our cloud provider who mercifully rains more compute on us whenever we need it!
To go along with that, I’m assuming our engineers are top-notch and are accounting for the difficulties of data storage at scale, since the CAP theorem tells us we either need to deal with slow writes, slow reads, or inaccessible data at some point. Pick your favorite and write some code to compensate for it! I’m assuming the team can also deal with the many other issues that come with distributed systems at scale, like thundering herds crushing dependencies. On top of that, I’m also going to assume that someone has dealt with the difficulty of deployment at this scale, from building and testing to artifact storage to rollouts and beyond.
Also, while not directly related to scaling workloads in terms of handling more operations, I am assuming our codebase is largely maintainable and bug-free. This is an entire dimension of operating at scale that we haven’t covered. It’s out of the scope of this article, but I do think writing large amounts of code comes with its own scalability problems (where the operations are maybe changes to the codebase? Tests? Engineering hours?) and should be considered in any discussion about language.
In other words, under the perfect conditions with the perfect engineers, yes, I think any language can scale. But under real circumstances with real constraints, I think some languages cap out much faster than others.
Real constraints
What are the real constraints that should factor into the language discussion? We already talked about time. Normally people also care about money. There are other resource constraints that crop up, like CPU and RAM, database connections, and IP addresses, as mentioned. More CPU use means more time taken, more money spent, and more servers needed as the CPU is eaten up. That means more IPs used and more database connections created. To me, reducing CPU usage is the biggest lever you can pull with language choice; it affects nearly every real constraint.
Also, I know I said I wouldn’t go into this too much in this article, but another real constraint is correctness. In fact, it’s probably the most important constraint—so important that I’ve taken it for granted this entire time. But while I assumed before that we had perfect engineers writing perfect code, the reality is that some languages are much harder to get right than others.
Correctness can also impact other constraints. For instance, since some languages are trickier for writing concurrent or parallelized code, we’ll often see them use serial implementations that then butt up against the time constraint we mentioned. Ideally, I’d like comparisons between languages to be, as they say in economics, ceteris paribus, but that’s difficult to achieve in reality. I’ll explore this in more detail in another article, but for now just keep it as a big caveat in the back of your mind.
Enough blabbing, tell us your real thoughts
To quickly recap, we’ve seen that any discussion of scalability is really a discussion about constraints, and constraints are normally left as unspoken assumptions anytime there’s a LinkedIn language argument. So, to try to start a real discussion I went ahead and revealed my assumptions underlying my claim that theoretically any language can scale, and also noted that under real conditions some languages will struggle to meet certain constraints before others. The real constraints I think we want to consider, pretty much in order of strictness, are time, money, and resource constraints like CPU, RAM, available IP addresses, database connections, and so on.
Please also note: I am not claiming that there are languages that won’t scale. However, I am firmly convinced that some languages scale better than others. This comes down to, as mentioned earlier, their ability to control the growth rate of the operations required to handle more load.
Our earlier examples of binary search and linear search don’t quite work here to explain the operations growth rate from language to language. As far as I know, there aren’t languages that have O(log(n)) runtime for handling more CPU instructions. I’m fairly confident that each language will grow its instruction set linearly. However, the coefficient that normally gets ignored in Computer Science 101 actually matters a lot to this discussion. With a slight hand wave we could even say that the coefficient is the main differentiator.
I explored this a little bit in an earlier article about language choice and cost savings. I didn’t talk about the scaling factor explicitly, but I did include this paper comparing energy usage of different languages. If we take energy use as a proxy for CPU instructions (which, as the paper explains, is not quite accurate, but I think it’s close enough for our purposes), we can build a table of each language’s coefficient of operations growth.
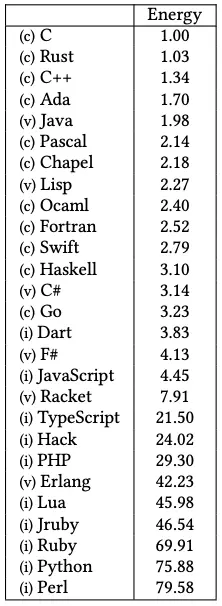
And with our table of coefficients in place, we can start to predict how these languages will scale their CPU use. That in turn can tell us something about how much our workloads will cost, and at what points we’ll run into other resource constraints.
CPU usage and cost constraints
To start, I’ve charted how the number of CPUs scales for some popular languages. The x axis is an arbitrary unit representing load on the system. The point isn’t to get an exact picture of how many CPUs are needed to handle a certain number of requests or anything like that. That will vary based on the use case anyway. The point here is to see how these different languages scale their CPU usage relative to each other when faced with the same loads.

Unsurprisingly given our scaling coefficients, we can see that Python and Ruby consume much more CPU than C, Rust, or C++. Java is also quite low on the chart, as is Go. Even Javascript is surprisingly low compared to Python and Ruby!
This same chart can also inform our monetary constraint, since cost is largely driven by CPU usage. If you’re using Amazon’s ECS Fargate offering, the price per CPU hour is an order of magnitude larger than the price per GB of RAM, so unless your workload requires upwards of 10 GB per CPU, I tend to abstract that cost away in my mind. That means we can get the approximate hourly cost of any of these workloads by simply multiplying the number of CPUs by $0.03238, which is the current price per hour in us-east-2 for a Linux/ARM CPU.
Let’s look at an example: say you’re running a Go workload that requires 1000 CPUs. From experience I’d say this is about the scale of a web app with a million users. Your monthly cost would be roughly $23,000 for compute. Now let’s say you were running that same workload with Python: since we’re estimating Python consumes about 24x as much CPU as Go, we’d expect costs to 24x as well. The same workload would be costing you nearly $550,000 a month in compute. Without going into too much detail to preserve everyone’s propriety, I’ll just say that these numbers do track with reality. They’re estimates, but they actually comport with real bills that real companies are paying right now. So, it’s worth asking yourself when you’re choosing a language: at a million users on my app, do I want to be paying $23k or $550k? Depending on your average monthly revenue per user, the choice could decide whether your company lives or dies.
Server and IP constraints
I also went ahead and plotted how many servers you’d need depending on your language choice. I assumed 8 CPUs per server (the max an ECS task can have), but if you’re running on EC2 you can have up to 64 CPUs per instance, so scale what you see here in accordance with what you’re using.
I included a dotted line showing the max number of IPs available to you in an AWS account (65,536). That’s to illustrate a point I made earlier: under real conditions there are frustrating thresholds that come up as you scale. Some languages run you into that kind of threshold sooner than others.

If we look at our hypothetical Go vs Python scenario again, we can try to contextualize that IP threshold a little bit. With a 1000 CPU Go workload, we’d need 125 ECS tasks (assuming 8 CPUs per task). With Python, we’d need 2,938 ECS tasks. Neither of those are anywhere near the IP address limit, so at a million users the monetary constraint is definitely a bigger factor than this particular resource constraint. You’d have to roughly 22x traffic to start running into an issue here. Take that with a grain of salt of course: if you’re running smaller tasks with 1 or 2 CPUs, that will eat up IPs much faster.
Database connection constraints
Lastly I want to look at database connections since those are also a finite resource. Each connection eats up a bit of memory, so the max number of connections is determined by how much memory your RDS instance has. Assuming we’ve got the largest amount of RAM available to us, 512 GB, and we’re using Postgres, the theoretical max number of connections one RDS instance could have is 53,717.
I assumed each server spawns 5 database connections per CPU, based on some prior experience I have configuring Ruby on Rails and Gunicorn. Both spin up one worker per CPU, then spin up a few threads per worker and each thread gets its own connection. I know other languages will do it other ways—for instance I give my Rust services a shared connection pool—but I think about 40 connections per server is still a fair estimate.

We can see by the dotted line that this constraint affects us much sooner than the IP address limit does! Turning back to our hypothetical one more time, if we’re running 125 Go ECS tasks, we’d be spawning about 5000 database connections. This is actually the max that Postgres allows by default. You have to alter the default settings to get more, which is something our Python workload will very much have to do. At 2,938 ECS tasks, we’re looking at 117,520 database connections. Oof.
There are a few decent solutions available though. You could create one or more read-replicas and start splitting up reads and writes between the instances. Or—honestly the thought of still having to explain this is kind of exasperating—you can architect your application well such that there are clear boundaries around independent domains, and each domain can get its own datastore. There are so many benefits to this approach: limited blast radius on failures, smaller surface area for security breaches, a smaller resource that an individual team can understand and take ownership of, and self-enforcing separation of data models which supports high cohesion and low coupling, which in turn leads to more maintainable code. Good architecture encourages good architecture in this case. And more salient to our current discussion, this approach removes the burden of the connection constraint, perhaps permanently. Depending on the use case, it’s unlikely you’d come up on the max until you reach tens of millions of users, which is frankly a problem that most companies would need to win the lottery to have.
Last thoughts
My main takeaway is that there are plenty of good languages with a relatively low scaling coefficient, and they’re certainly worth choosing over Ruby or Python. We’ve seen that this scaling coefficient has a very real impact on your compute spend, and a noticeable impact on common resource constraints once your audience reaches a certain size, so I think it makes sense to steer clear of the worst offenders. If you can stomach it, I’d say it’s worth even avoiding TypeScript. You can still have types, but you’re going to get a lot more bang for your buck if you pick something that does its type checking as part of compilation. Heck, if you don’t want types then JavaScript is actually not a bad choice!
As for me, I love Rust; it scales almost as well as C and it’s a joy to write, which is why I’m using it for my startup as well as at work when I can. You don’t need to jump on that bandwagon though. Java had an incredibly low coefficient, as did Go. Kotlin wasn’t in the study, but I bet it’s close to Java, and while I didn’t plot C#, it was also a contender with Go.
Take this all with a disclaimer: I only covered a few kinds of constraints that I have seen and dealt with firsthand, that I know are common problems. And the examples given here may not all be applicable to you (i.e. database connections might be irrelevant depending on the data stores you use), but hopefully they serve as food for thought. I think to get this discussion right we all need to work to understand the constraints in our particular domains, and your conclusions might be different than mine.
Thanks for reading this far! In the spirit of good discussion, and of digging into assumptions and constraints, please write up a response if you feel so inclined and post it! You can reach me on Medium (just leave a comment on an article), or on LinkedIn if you want to send it my way. Best of luck with everything you build!
