(Message) Order out of Chaos: Part 2 of 3

- Event-Driven Dumpsterfire: Part 1 of 3
- (Message) Order out of Chaos: Part 2 of 3
- Coming soon! Part 3 of 3
I heaved a sigh as I posted a third, nearly-identical PR to our team Slack channel for review. Another team had updated an event we relied on. Unfortunately, we relied on it in three different services in almost the same exact way.
In a meeting later that day with a principal engineer, I mentioned the duplicated efforts. I figured he’d be interested generally, but I also hoped he’d have some specific insights given that he had been the tech lead of my team before me. His name was all over the initial commits of two of these services.
He paused. Then he said “Separate the offers from the rewards”. I furrowed my eyebrows a little bit and stared up at the trim around my door. I didn’t quite see the difference, and he must’ve noticed I hadn’t caught on because he continued: “These offers all work a little different, which is why we’ve got three services. But the rewards are all issued pretty much the same way”. I nodded.
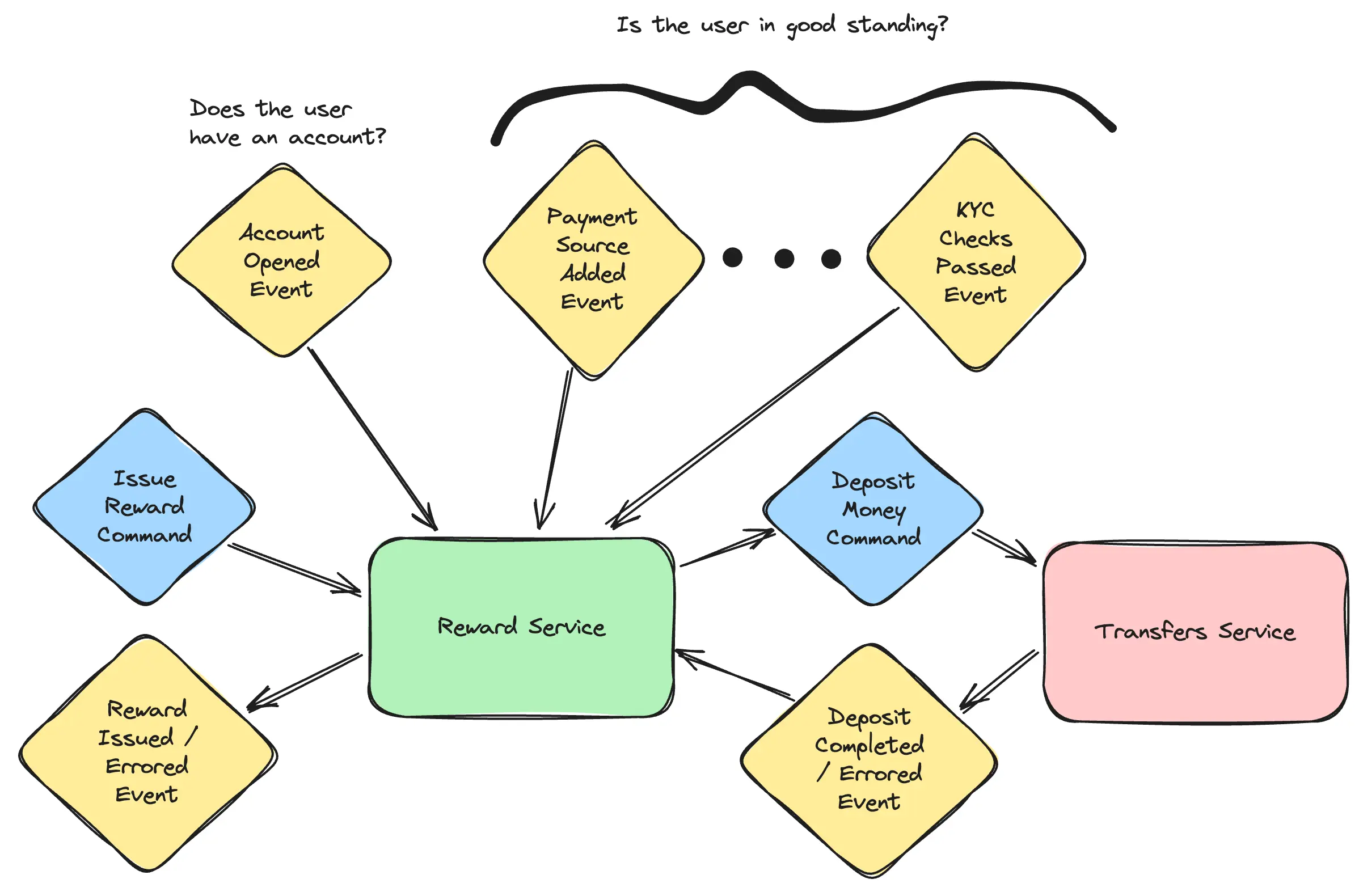
As the tech lead of the growth team, I’d been working on services to power incentives, referrals, and reactivation offers. The offer functionality was indeed a bit different between them, as were the use cases. Incentives were involved in all manner of acquisition endeavors, as well as activation and product marketing email campaigns. Referrals were for acquisition, and also tied in with our live events. Meanwhile, reactivation offers were of course there to help prevent churn, giving users a little perk if they decided to stick with their subscription another month. There might’ve been room to consolidate—reactivation probably could’ve been powered by the incentive service for instance—but the even lower-hanging fruit really was issuing the rewards. Regardless of how the offers were made or how their state was managed, all three services contained the same logic for getting a reward to a user who met the conditions on their offer.
At a high level, the logic was:
- make sure the user has an open account to deposit the reward into
- make sure the user is in good standing (i.e. make sure the user wasn’t fraudulent), and then
- make a call to the transfers service to deposit a monetary reward into the user’s account
My refactoring had to happen because one of the events carrying data for step 2 had changed.
We didn’t jump on the project right away, but we did eventually decide to split reward issuance out into its own service. We wanted to test new “voucher” functionality, which had been on the backlog for quite some time, and refactoring reward issuance into its own service would make vouchers much simpler. We could write the feature in one place rather than spew nearly identical code across three services. It was a win-win to simplify our old services while making it quicker and safer to add the new feature.
I started scaffolding out what the new reward service would need. We all agreed it’d aggregate the data it needed for steps 1 and 2 by listening for events. It would send an async command to the transfers service for step 3. In turn, it’d be listening for async commands coming from clients to know when to issue a reward in the first place. It would “respond” to commands by publishing an event that clients could listen for once the reward was successfully issued.
The Chaos
Now, the surprise is somewhat spoiled since it’s in the title of this article and we talked about it in part 1, but the biggest issue facing this new reward service was message ordering.
In its prior form, the reward issuing logic had some assumptions it could fall back on to ensure proper ordering. For instance, the referral service wouldn’t allow a user to send a referral until they had an account and were in good standing. That guaranteed they were eligible for the reward when it came time to issue one.
However, with vouchers we wanted to relax those restrictions, meaning we could no longer assume anything about the user’s state. Relaxing the restrictions was great for the business, since it meant users could send referrals and receive other offers before successfully opening a deposit account or completing onboarding. That increased our pool of potential referral senders, as well as our pool of users we could send incentives to. But it was tricky for our logic since it meant a command could come in to issue a reward before a user was in a valid state to receive it.
The Order
Without the guarantee that a user would be in a good state before receiving a reward, the reward service needed to track user state on top of voucher state. Vouchers needed to be issued without being redeemed, and then ideally automatically redeemed once the user was in a good state.
Automatic redemption posed the greatest challenge. Since we know async event timing is arbitrary, and there are therefore no ordering guarantees when events are coming from multiple publishers, we couldn’t assume any particular message could tell us when a voucher was ready to be redeemed. Just because an event came through saying the user had added a payment source did not mean they had also successfully opened a deposit account with us. We had to treat each event independently and ask after each one: can the voucher be redeemed now? By keeping track of user state and updating it as each new event came in, it was easy to run the redemption check after each event. This eliminated any assumptions about order and allowed us to correctly redeem vouchers regardless of how the user data flowed in.
Another benefit of checking after each state update was that we could correctly redeem in cases where a user started in bad standing (i.e. appeared to be fraudulent), but then later corrected their information and transitioned to a good state. It wasn’t enough to receive an event saying a user had created an account; the event actually had to indicate that the account was open and had passed fraud and KYC checks. If the user had to edit their account and multiple account-related events streamed through, the reward service was able to check after each update whether the user was finally in a good state. Once they were, the voucher would be redeemed.
So far the solution was looking promising: allow the service to build up a user state in arbitrary order and check whether the voucher was fit to redeem after each update. Once the user state was complete and the data indicated the user was in good standing, the voucher would be redeemed. But what if the user was already in a good state when the command to issue a reward came through? We had removed ordering assumptions from the events carrying user state, but we still had one last ordering assumption to get rid of: assuming that the command would arrive before the events would.
Luckily, the fix was simple: perform the same redemption check after receiving the command. Despite some semantic differences between events and commands, both types of async message were necessary to fulfill the voucher redemption requirements. Both types carried relevant data and made relevant changes to either user or voucher state. And since both states needed to be considered, it made since to perform the same check after any update to account for every possible message ordering we might receive.
Closing Thoughts
At the end of the day, getting rid of ordering assumptions means abstracting away the means of data delivery. From the point of view of the redemption logic, there are no events or commands: there’s only the user and voucher state. That state acts as an interface allowing the data to arrive however we’d like: one async message, two async messages, ten async messages and a synchronous request, whatever—all the redemption code needs to do is look at the state. It is totally ignorant of how the state gets there.
One note about performance: since this same redemption check was running after every async message the reward service received, it was worth taking a minute to optimize that code! I stored each distinct aspect of user and voucher state in a separate table keyed off of the user id. This allowed me to query for each part in parallel, making my database calls only as slow as the slowest call. If any of it was missing, I could short-circuit the check and move on. Since each query was a simple indexed lookup from a database living in the same datacenter as my server, the state lookup remained in the single digit milliseconds. Of course with enough volume this could really overwhelm a database and start to impact latencies, or blow up a usage bill. Another approach, if your product requirements allow it, might be to schedule redemption checks with a cron job and perform database operations in bulk. It might not be as real-time, but it could save a lot of network overhead. You may also be able to leverage caching or other techniques like Bloom filters depending on your application.